导语:目前,比特币 Layer2 已经成为一股热潮,市面上自我定位为“比特币 Layer2”的项目,据说已有数十家。其中,不少自封为“Rollup”的比特币 Layer2,声称采用了 BitVM 白皮书提出的方案,使得 BitVM 成为比特币生态的显学。
但无奈的是,目前大多数关于 BitVM 的文字资料,都未能通俗的解释其原理。
本文是我们读过了 BitVM 只有 8 页的白皮书后,查阅了与 Taproot、MAST 树、Bitcoin Script 相关的资料后,得出的简单总结。为了便于读者理解,其中一些表达方式与 BitVM 白皮书中阐述的内容不同,我们假定读者对 Layer2 有一些了解,并能够理解“欺诈证明”的简单思想。

先几句话概括 BitVM 的思路:无需 on chain 的数据,先在链下发布并存储,链上只存放 Commitment(承诺)。
发生挑战/欺诈证明时,我们只把需要上链的数据 on chian,证明其与链上的 Commitment 存在关联。之后,BTC 主网再校验这些 on chian 的数据是否有问题,数据生产者(处理交易的节点)是否有作恶行为。这一切都遵循奥卡姆剃刀原则——“若非必要,勿增实体”(能少 on chain,就少 on chain)。

正文:所谓的基于 BitVM 的 BTC 链上欺诈证明验证方案,通俗总结:
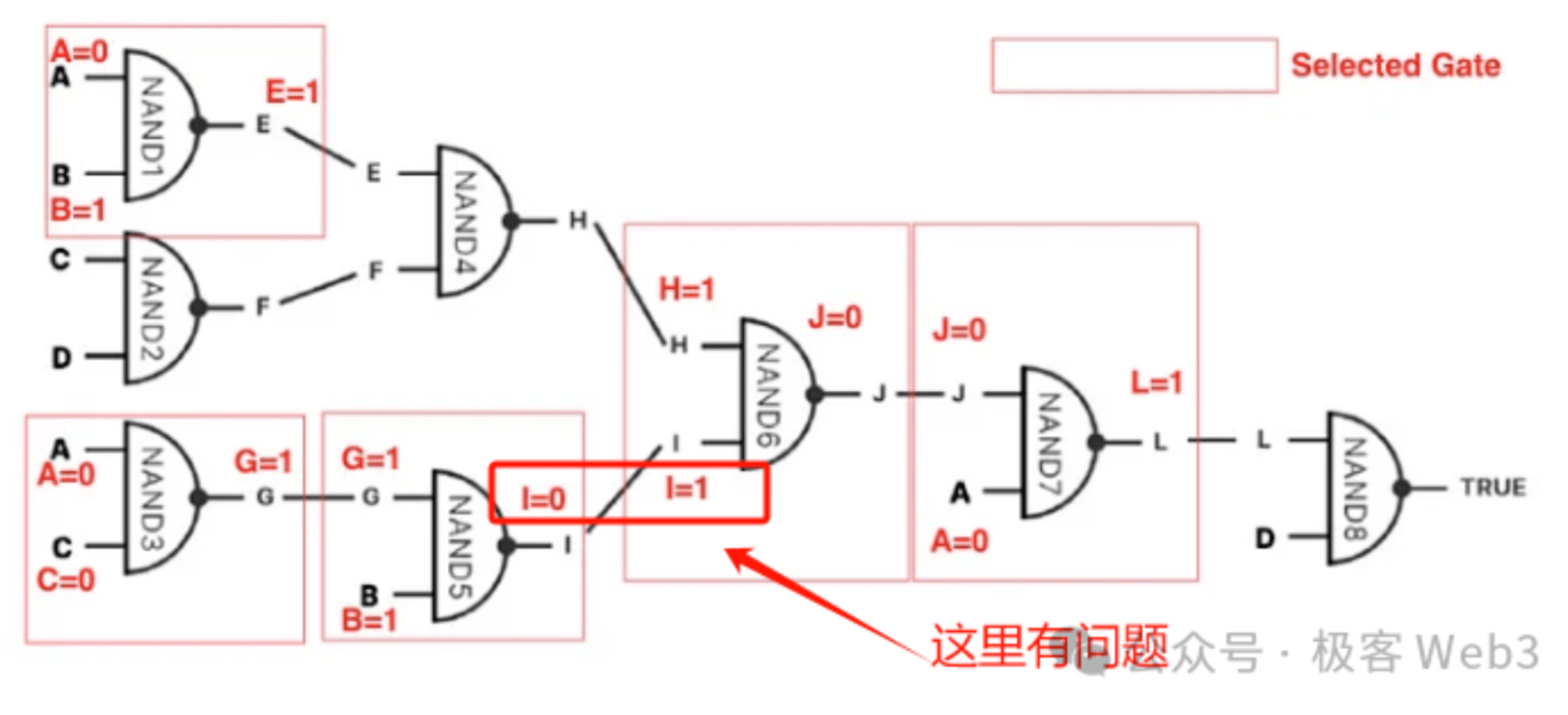
1.首先,计算机/处理器,是一个由大量逻辑门电路组合成的输入 - 输出系统。BitVM 的核心思路之一,是用 Bitcoin Script(比特币脚本),模拟出逻辑门电路的输入 - 输出效果。
只要能模拟出逻辑门电路,理论上就可以实现图灵机,完成所有可计算任务。也就是说,只要你人多钱多,就可以召集一帮工程师,帮你用功能简陋的 Bitcoin Script 代码,先模拟出逻辑门电路,再用巨量的逻辑门电路实现 EVM 或是 WASM 的功能。
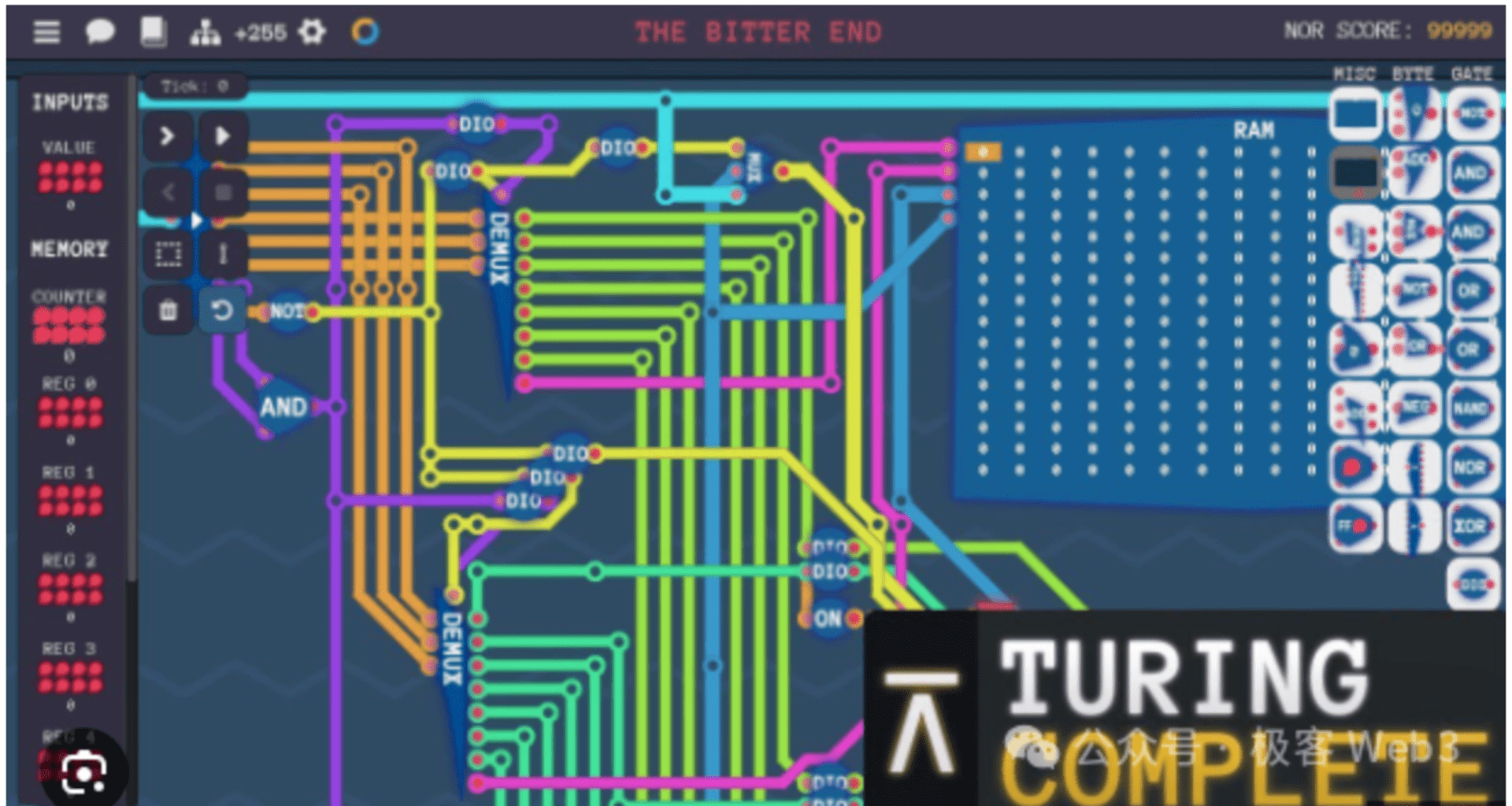
(此截图来自于一款 教学游戏:《图灵完备》 ,其中最核心的内容,就是用逻辑门电路尤其是与非门,搭建出完整的 CPU 处理器)
有人曾将 BitVM 的思路比作:在《我的世界》里,用红石电路做一个 M1 处理器。或者说,相当于用积木撘出来纽约帝国大厦。
2.那么,为什么非要用 Bitcoin Script 模拟 EVM 或 WASM?这样不是很麻烦吗?这是因为大多数比特币 Layer2 往往选择支持 Solidity 或 Move 等高级语言,而目前可以直接在比特币链上运行的,是 Bitcoin Script这种简陋的、由一堆独特操作码组成的、非图灵完备的编程语言。
(一段 Bitcoin Script 代码示例)
如果比特币 Layer2 打算像 Arbitrum 等以太坊 Layer2 一样,在 Layer1 上验证欺诈证明,极大程度继承 BTC 安全性,需要在 BTC 链上直接验证“某笔有争议的交易”或“某个有争议的操作码”。如此一来,就要把 Layer2 采用的 Solidity 语言 / EVM 对应的操作码,放在比特币链上重新跑一遍。问题归结为:
用 Bitcoin Script 这种比特币 native 的简陋编程语言,实现出 EVM 或其他虚拟机的效果。
所以,从编译原理的角度去理解 BitVM 方案,它是把 EVM / WASM / Javascript 操作码,转译为 Bitcoin Script 的操作码,逻辑门电路作为“EVM 操作码 ——> Bitcoin Script 操作码”两者之间的一种中间形态(IR)。
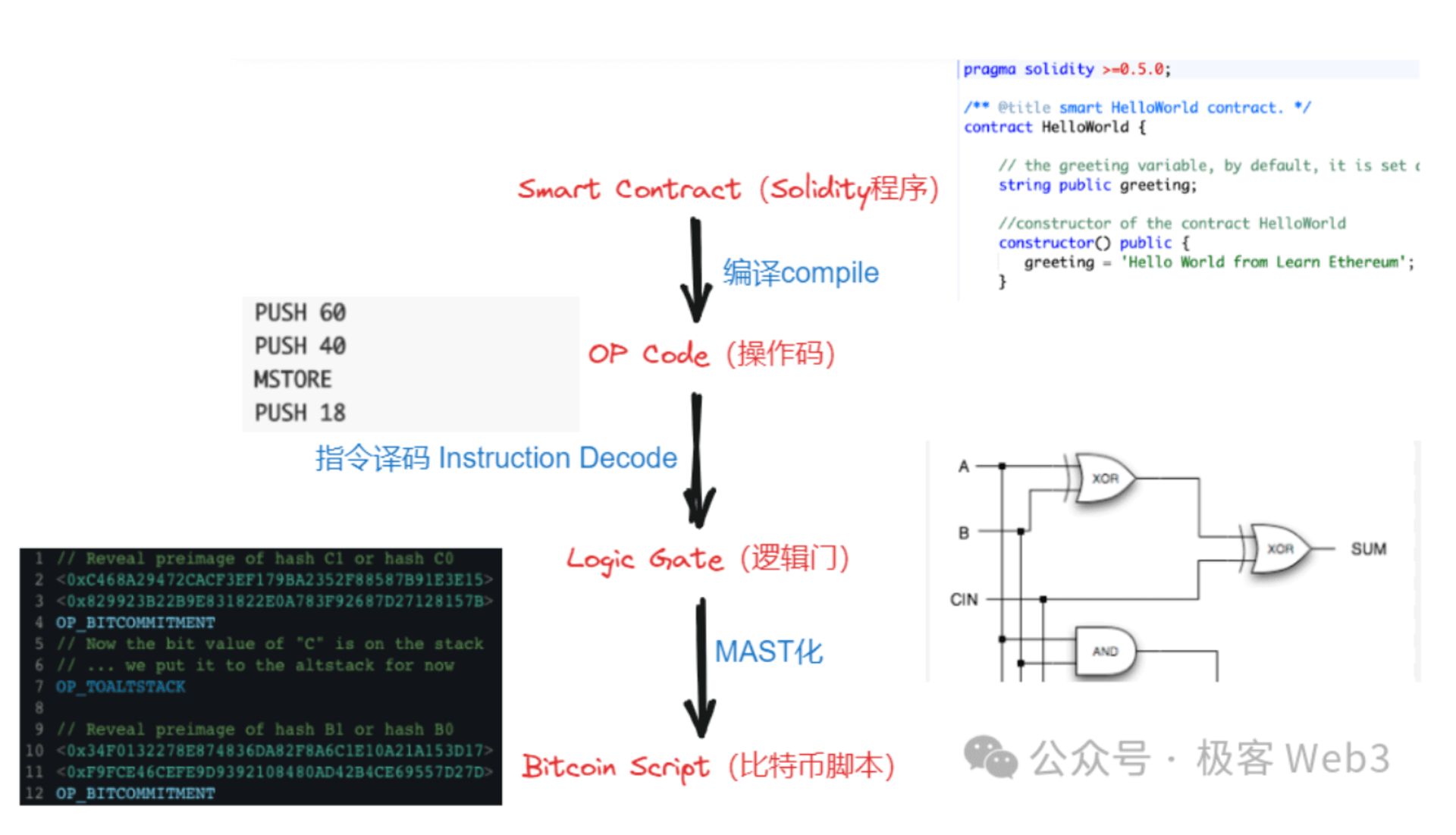
(BitVM 白皮书里,谈到在比特币链上执行某些“有争议的指令”的大致思路)
Anyway,最终模拟出的效果是,把原本在 EVM / WASM 上才能处理的指令,放到比特币链上直接处理。这个方案虽然可行,但难点在于,如何用大量的逻辑门电路作为中间形态,表达出所有的 EVM / WASM 操作码 op code。而且,用逻辑门电路的组合,直接表达某些极为复杂的交易处理流程,可能产生巨大的工作量。
3.下面说下 BitVM 白皮书中提到的另一个核心,也就是与 Arbitrum 高度相似的“交互式欺诈证明”。
交互式欺诈证明会涉及到一个称为 assert(断言)的词,一般而言,Layer2 的提议者 Proposer(往往由排序器充当),会在 Layer1 上发布 assert 断言,声明某些交易数据、状态转换结果,是有效无误的。
如果有人认为 Proposer 提交的 assert 断言有问题(关联的数据有误),就会发生争议。此时,Proposer 和 Challenger 会回合式的交换信息,并对有争议的数据进行二分法查找,快速定位到某个粒度极细的操作指令,及其关联的数据片段。
对这个有争议的操作指令(OP Code),需要连带其输入参数在 Layer1 上直接执行,并对输出结果作出验证(Layer1 节点会把自己计算得到的输出结果,与 Proposer 之前发布的输出结果进行对比)。在 Arbitrum 里,这被称为“单步欺诈证明”。

(Arbitrum 的交互欺诈证明协议中,会通过二分法检索 Proposer 发布的数据,尽快定位到有争议的那条指令及执行结果,最后发送单步欺诈证明到 Layer1,进行最终验证)
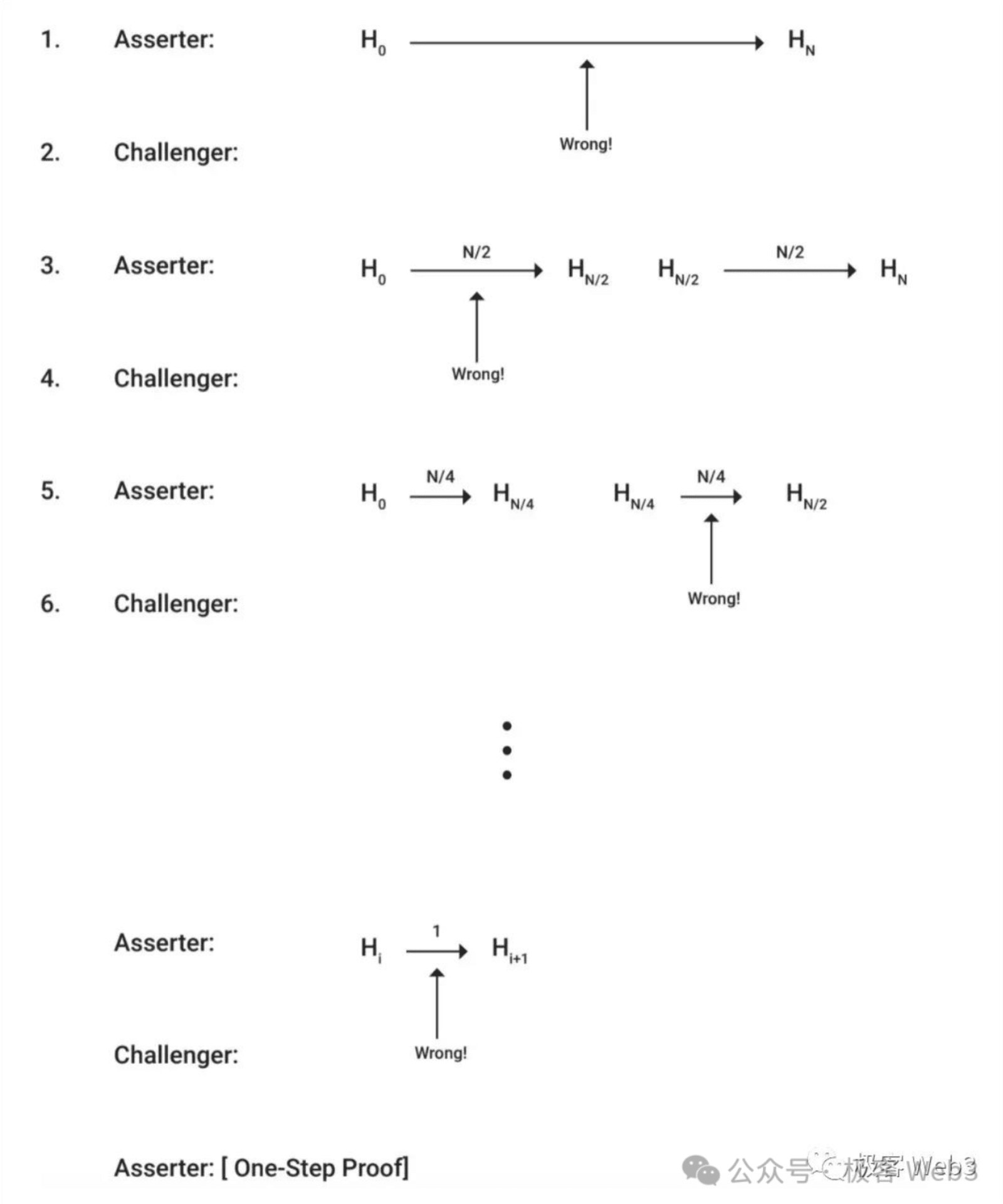
(Arbitrum 的交互式欺诈证明流程图,阐述的比较粗糙)
到了这里,单步欺诈证明的思路很好理解了:绝大多数发生在 Layer2 的交易指令,不需要在 BTC 链上重新验证。但其中某个有争议的数据片段/操作码,在被人挑战时要在 Layer1 重放一遍。
如果检测结论为:Proposer 之前发布的数据有问题,则 Slash 掉 Proposer 质押的资产;如果是 Challenger 有问题,则 Slash 掉 Challenger 质押的资产。如果 Prover 长时间不响应挑战,也可以被 Slash。
Arbitrum 通过以太坊上的合约来实现上述效果,BitVM 则要借助 Bitcoin Script 实现时间锁、多签等功能。
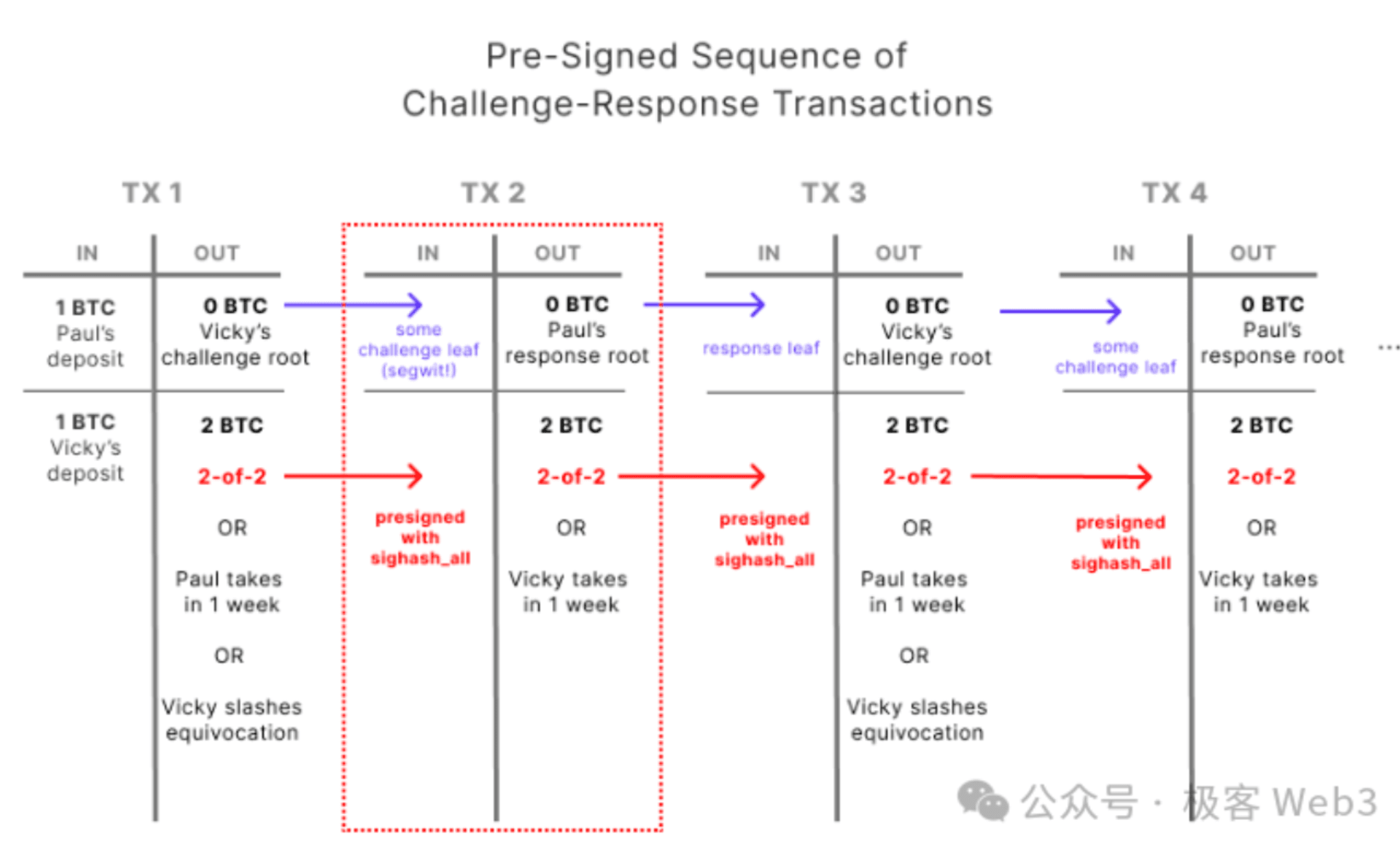
4.简单讲完“交互式欺诈证明”与“单步欺诈证明”后,我们将谈及 MAST 树和 Merkle Proof。
前面谈到,BitVM 方案中,不会将 Layer2 在链下处理的大量交易数据/涉及的巨量逻辑门电路 直接 on chain,只在必要时刻将极少数据/逻辑门电路 on chian。
但是,我们需要某种方式,证明这些“原本在链下,现在要 on chain”的数据,不是随手捏造的,这就是密码学中常提到的 Commitment。Merkle Proof 就是 Commitment 的一种。
首先,我们说下 MAST 树。MAST 树全名为 Merkelized Abstract Syntax Trees,是把编译原理里涉及的 AST 树,转化为 Merkle Tree 之后的形态。
那么,AST 树又是什么?它的中文名是“抽象语法树”,简单的讲,就是把一段复杂的指令,通过词法分析,细分为一堆基础的操作单元,然后组织为一棵树状的数据结构。
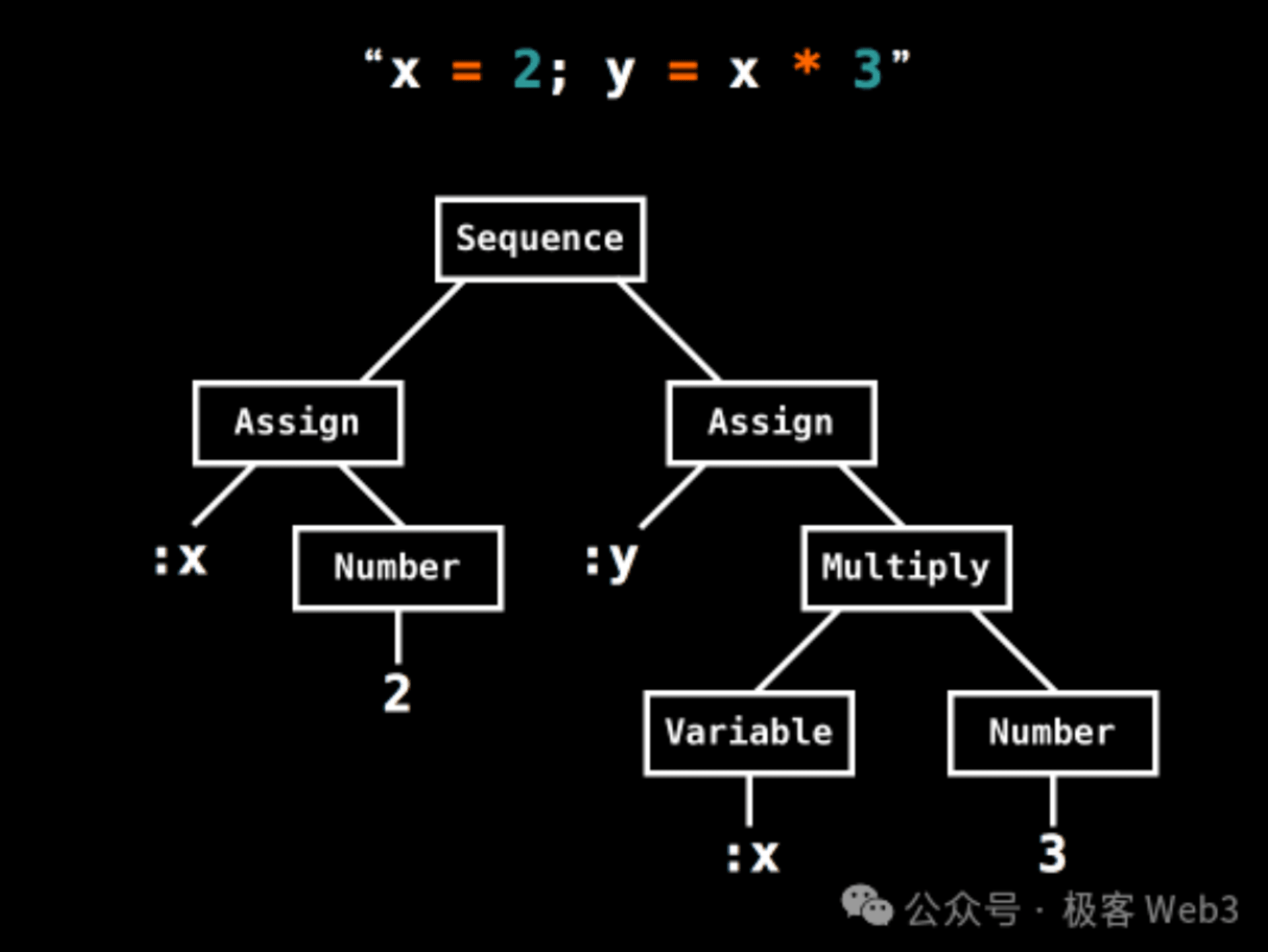
一个 AST 树的简单案例,这棵 AST 树将 x=2,y=x*3 这样的简单运算,细分为了底层操作码 + 数据)
而 MAST 树,就是把 AST 树 Merkle 化,以支持 Merkle Proof。Merkle 树有一个好处,就是它可以实现高效率的“数据压缩”。比如,你想在必要时,将 Merkle 树上的某段数据发布到 BTC 链上,但又要让外界确信,这个数据片段确实存在于 Merkle 树上,而不是你“随手拈来”的,怎么办?
你只要事先将 Merkle 树的 Root 记录在链上,在未来出示 Merkle Proof,证明某段数据,存在于 Root 对应的 Merkle 树上,就行。
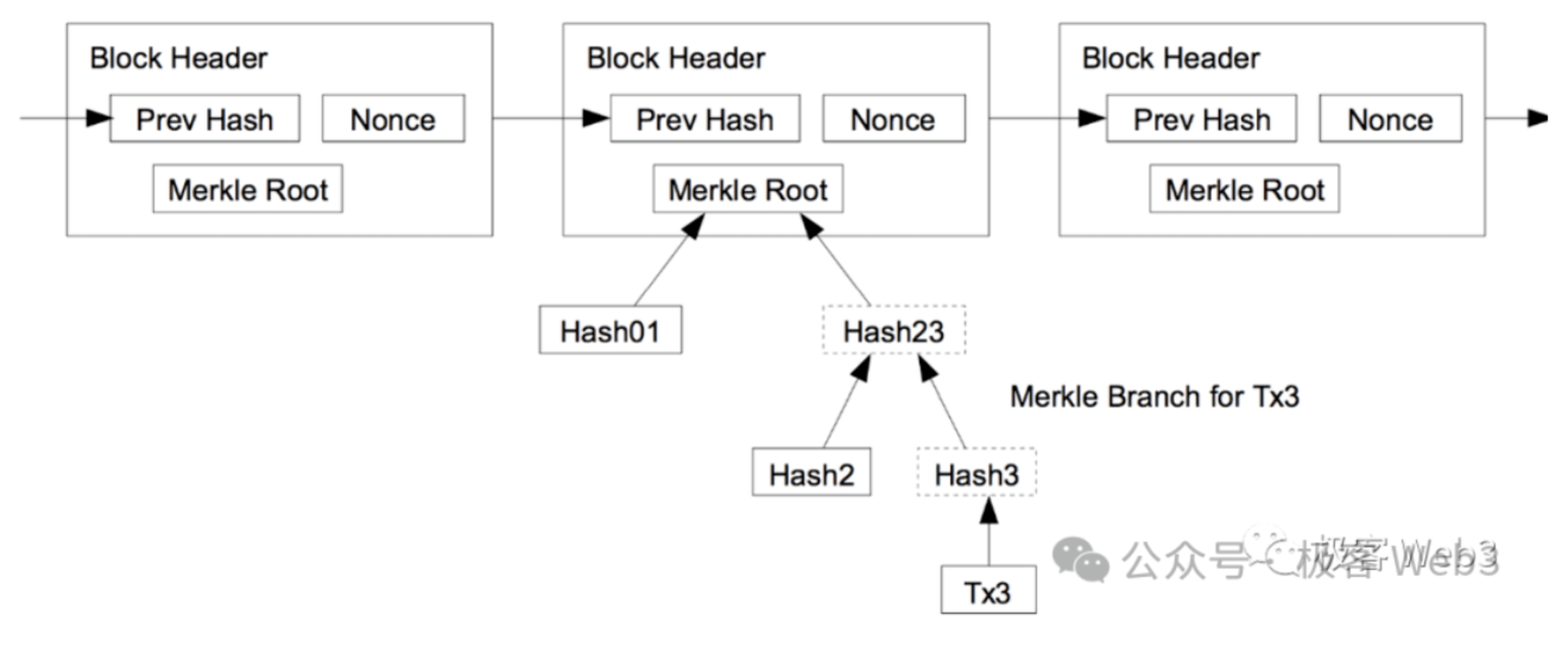
(Merkle Proof/Branch与Root之间的关系)
所以,无需将完整的 MAST 树存放在 BTC 链上,只需要提前披露其 Root 充当 Commitment,在必要时出示 数据片段 + Merkle Proof /Branch 即可。这种可以极大程度压缩 on chain 的数据量,且能保证 on chain 数据真的存在于 MAST 树上。而且,仅在 BTC 链上公开小部分数据片段+Merkle Proof,而不是公开所有数据,能起到很好的隐私保护效果。
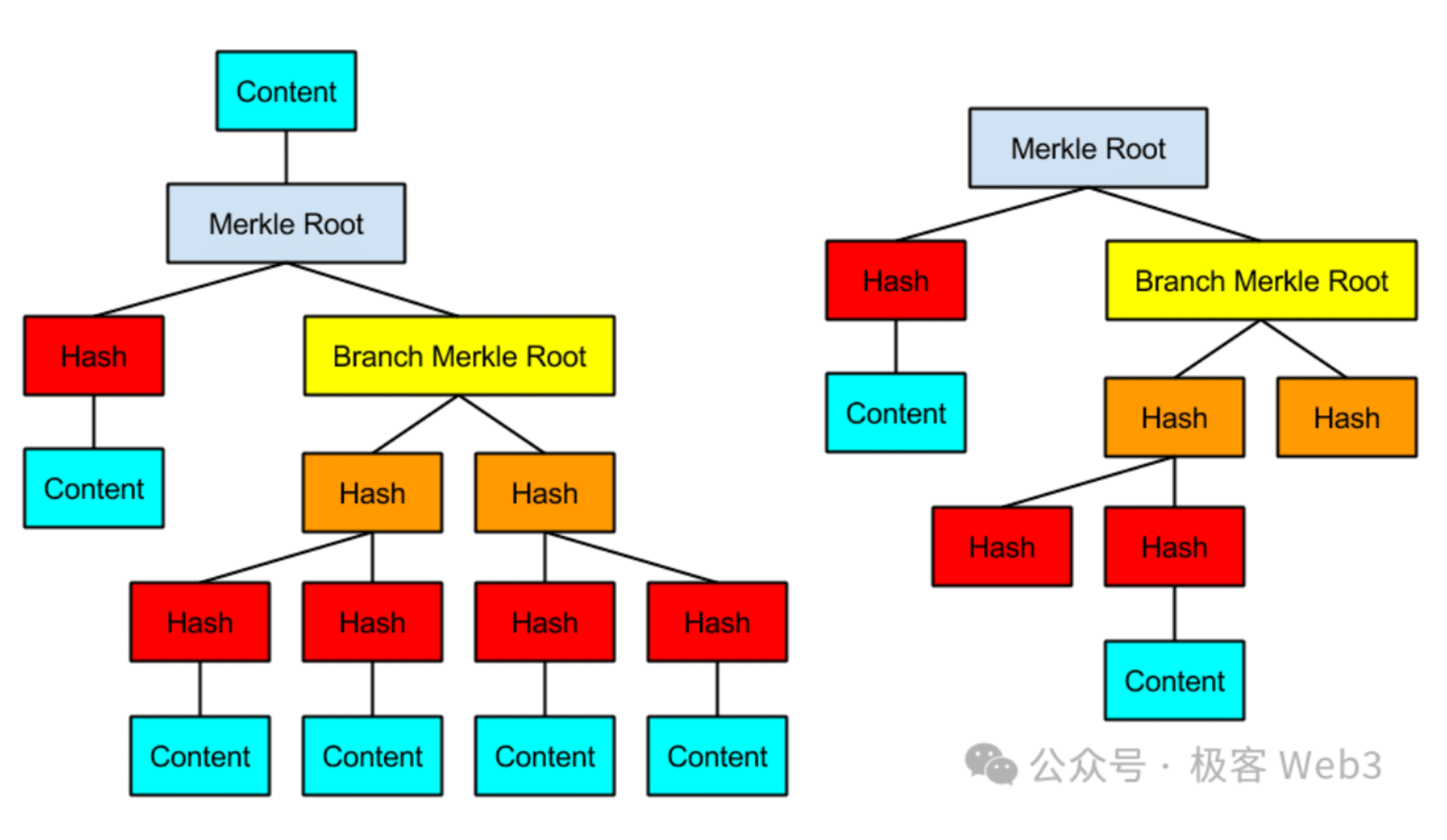
(MAST 树示例)
BitVM 的方案,尝试把所有的逻辑门电路用比特币脚本表达出来,再组织成一个巨大的 MAST 树,这棵树最底下的叶子 leaf(图中的 Content),就对应着用比特币脚本实现的逻辑门电路。
Layer2 的 Proposer,会频繁的在 BTC 链上发布 MAST 树的 root,每棵 MAST 树,都关联着一笔交易,涉及其所有的 输入参数 / 操作码 / 逻辑门电路。某种程度上,这类似于 Arbitrum 的 Proposer 在以太坊链上发布 Rollup Block。
当争议发生时,挑战者在 BTC 链上声明,自己要挑战 Proposer 发布的哪个 Root,然后要求 Proposer 揭示 Root 对应的某段数据。之后,Proposer 出示默克尔证明,反复在链上披露 MAST 树的小部分数据片段,直到和挑战者共同定位到有争议的逻辑门电路。之后就可以执行 Slash。
5.到这里,BitVM 整个方案最重要的部分基本讲完,虽然其中某些细节还是有点晦涩,但相信读者已经可以 get 到 BitVM 的精华与要旨。至于其白皮书里提到的 bit value commitment,是为了防止 Proposer 在被挑战并被迫在链上验证逻辑门电路时,给该逻辑门的输入值“既赋值 0,又赋值 1”,产生二义性混乱。
总结:BitVM 的方案,先用比特币脚本表达逻辑门电路,再用逻辑门电路表达 EVM/其他 VM 的操作码,再用操作码表达任意一条交易指令的处理流程,最后组织成 merkle tree/MAST树。
这样的一棵树,如果表达的交易处理流程很复杂,很容易破 1 亿个 leaf,所以要尽量缩减 Commitment 占用的区块空间,以及欺诈证明波及的范围。
虽然单步欺诈证明,只需要 onchain 极小的一段数据和逻辑门脚本,但完整的 Merkle Tree 要长期存储在链下,以备有人挑战时,可以随时 onchain 树上的数据。
Layer2 每笔发生的交易,都会产生一个大号 Merkle Tree,节点的计算和存储压力可想而知,大多数人可能不愿意去运行节点(但这些历史数据可以被过期淘汰,而 B^2 network 专门引入类似 Filecoin 的 zk 存储证明,激励存储节点长期保存历史数据)
不过,基于欺诈证明的乐观 Rollup,本身也不需要有太多节点,因为其信任模型是 1/N,只要 N 个节点中有 1 个是诚实的,能够在关键时刻发起欺诈证明,Layer2 网络就是安全的。
但是,基于 BitVM 的 Layer2 方案设计中,还存在许多挑战,比如:
1)理论上说,为了进一步压缩数据,不必直接在 Layer1 验证操作码,可以将操作码的处理流程再度压缩为 zk proof,让挑战者对 zk proof 的验证步骤进行挑战。这样可以大幅度压缩 on chain 的数据量。但具体的开发细节会很复杂。
2)Proposer 和 Challenger 要在链下反复产生交互,协议该如何设计,Commitment 和挑战过程,该如何在处理流程上进一步优化,需要消耗很多脑细胞。
参考文献:
作者:雾月 & Faust,极客web3
顾问:Kevin He, BitVM 中文社区发起人,ex Web3 Tech Head@Huobi